
SMT 2022 Presentation on EQ and Compression
"Some Embodied Poetics of EQ and Compression" presented November 12 2022

I was happy to present the following paper at the joint meeting of the Society for Music Theory, American Musicological Society, and Society for Ethnomusicology this past weekend in New Orleans. I’m reprinting it here for anyone interested. This paper is a partial sketch of the major themes that I am writing about in my book-in-progress: embodied music perception, technics, metaphors of construction and augmentation that artists have employed to describe their work, and the tools of the recording studio. In the talk I mixed the drums live, but I won’t do that here — you can compare the unmixed recording, mixed recording, and performance video, and trust that I gave a brilliant, virtuosic description of what I was doing and why. I will note that this mixing was done to be didactic and also done with a conference room’s sound system in mind, so it is overly dramatic.
I’d be very grateful for your feedback and thoughts as I continue to work on this project.
Some Embodied Poetics of EQ and Compression
I. Introduction
Audio equalization and dynamic range compression are ubiquitous recording techniques. Every piece of recorded music undergoes at least some EQ and compression. These techniques occupy as much real estate in audio engineering textbooks as august music theory texts spend on the cadential 6/4 or on modulation to the key of the dominant. But these techniques have not come under sustained scrutiny by music theorists, even though the field is in the midst of an efflorescence of scholarship on timbre, which EQ and compression manipulate. Two of the most sustained studies of the expressive import of studio techniques that I know of have come from Simon Zagorski-Thomas, who refers to these manipulated sounds as “sonic cartoons.” There is some truth to this, but I think Zagorski-Thomas’ emphasis on these modified sounds as caricatures is too wedded to a commitment to an ontologically “real” version of a sound that a recording “represents.” By contrast, I hope that incorporating recent scholarship on embodiment and mimesis might offer paths into thinking about these sounds as being meaningfully “real” in the bodies and minds of listeners in their own right, and to the kinds of creative and even liberatory attitudes toward sound that this stance might open up. These attitudes toward sound are not just scaffolded or enhanced by studio recording technologies but enabled by them.
My talk today has three aims: first, I will very briefly explain what EQ and compression are and what they do to recorded audio. I especially want to draw your attention to how these concepts are discussed in textbooks and pedagogical materials, essentially arguing that there is less utility in mining those resources for analytic ends than music theorists might hope or expect.
Then, I will do a quick mix of a recording of a drum set, highlighting some of the qualitative language that a mixing engineer might use to describe both the quantitative parameters controlled by EQ and compressors as well as the physical, acoustical correlates of the waveform itself. My overarching assertion is that the predominant creative use of EQ and compression is to change timbral features of a sound that correspond to qualitative perceptions of material, space, and exertion.
The last part of my talk will situate that assertion within recent research on timbre, affect, and 4-E (embodied embedded extended ecological) cognition. This work elegantly describes many of the expressive and musico-poetic features of these sounds, in a way that has descriptive utility for music analysts and also creative utility for audio engineers, producers, and other artists. I use the word “poetics” here and in my title particularly because of its relationship to theories of narrative. Introducing into conversations about timbre, affect, and embodiment the mixing process—with its layers of mediation, sociotechnical assemblages, improvisatory workflow, and so on—might productively complicate an overly humanistic frame of reference. I seek to sound a note of encouragement for scholars of timbre to continue to explore the nexus of timbre, embodied cognition, and technics.
II. EQ
Audio equalization (or EQ) originated in the early days of telephony, to help ensure that the signal that reached the listener matched the signal of the utterer. (Välimäki and Reiss 2016, 129). Today equalization refers to any alteration of the component frequencies of a sound. EQ thus happens at many stages in a recording session. It happens as a function of microphone selection, since different microphones boost or attenuate different frequency ranges—see for example the AKG P170 microphone’s manufacturer-indicated frequency response, which shows a low cut beginning around 60 hz and a boosted frequency response starting at 7,000 hertz and peaking at 10,000 hertz.
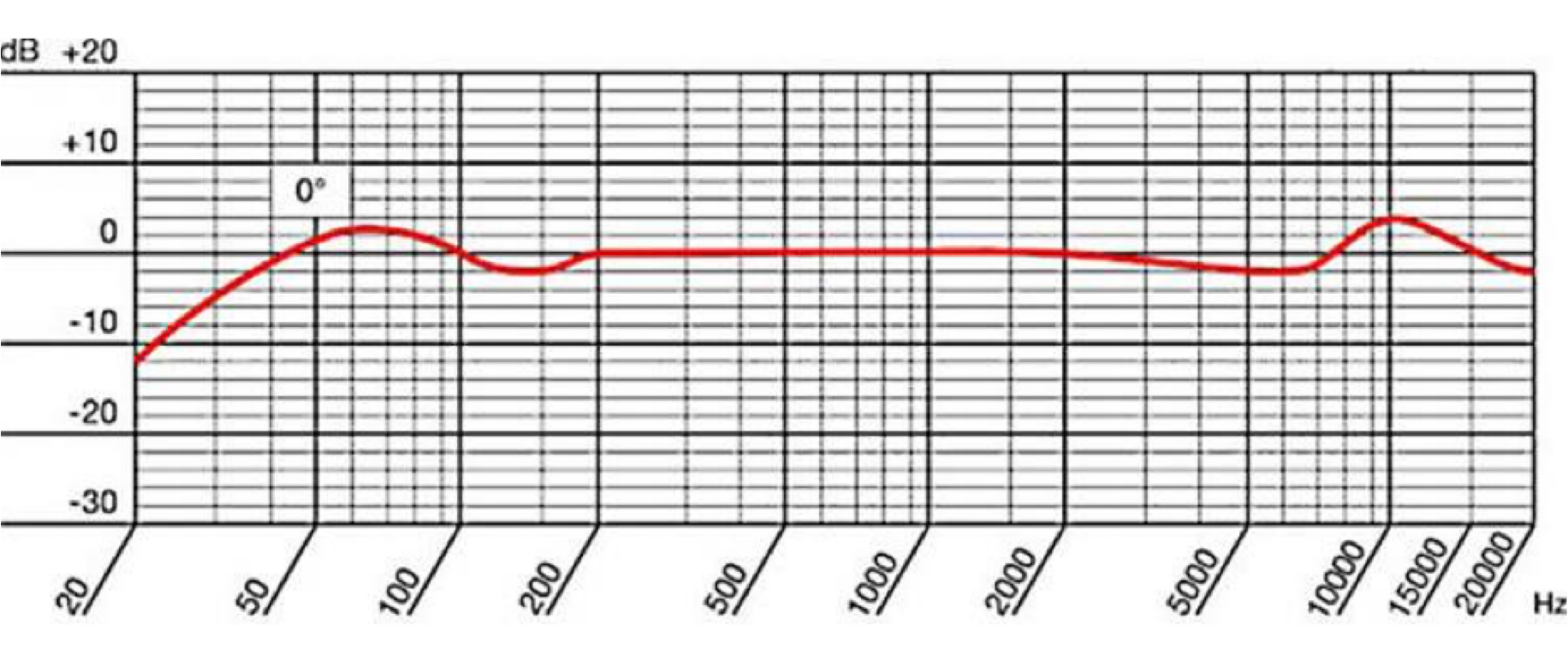
It also happens as a function of microphone placement: for example, microphones that are positioned off axis can attenuate higher frequencies, as shown in this chart of the AKG P414 XLII:

(source: https://townsendlabs.com/why-mic-axis-matters/ )
In general, the closer a microphone is to a source, the more of the source’s low frequencies it can register. (This is usually referred to as the proximity effect.)
And then the signal from the microphones may pass through a variety of outboard gear, including analog and digital equalizers and compressors, before arriving in the computer for yet more digital signal processing.
One use for EQ is reparative: perhaps an error in recording went undetected and now a buzzing bass amp is part of the mix. Needless to say this is highly undesirable because it requires making dramatic alterations to a particular part of a signal, and most professional recording situations would re-record the audio rather than try to fix it with EQ.
The more common use is much more creative: directing listener to attention to various aspects of a sound, and modifying those aspects. The audio engineering textbook “Audio Engineering Made Easy” by Tim Dittmar maps a few qualitative descriptors onto EQ techniques. For instance:
“Body – Depending on the frequency range of the instrument or voice, the lower frequency area would need to be dominant. Often people want to hear the body of an acoustic instrument, such as an acoustic guitar or snare drum. This request would require plenty of 100–250 Hz present in the sound.”
Or:
“Hard – A hard sound has a lot of midrange and accentuates the attack part of a sound’s envelope. Harder frequencies are found between approximately 1 and 4 kHz.”
Lastly: Engineers are cautious not to “over-mix” using EQ or compression, which risks breaking the immersive trance of listening to recorded music by drawing undue attention to the artificiality and constructedness of the recording. But as modern listeners, the vast majority of the music we encounter is recorded, and knowingly or not we have all cultivated the audile technique (per Jonathan Sterne) of accepting highly processed sound as representative of real objects and real performances. Our threshold for what sounds “processed” is much higher than we might like to think.
III. Compression
A compressor reduces the dynamic range of a performance. But one of the important things to note with compressors is that they are adaptive: what they do depends on the amplitude of the signal coming in. Compression does not just affect volume; it is not the same as if you were to automate your mixer’s volume fader.
Most audio engineering textbooks and conventional wisdom advocate for using several compressors in layers during the mixing process. This can yield a sound that has received rather heavy compression without necessarily sounding like it’s been so extensively processed, or without foregrounding compression as a special effect.
The user interface of most compressors asks the engineer to determine the volume over which certain sounds will be compressed; how much they will be compressed; and when to start and end the compression. These are represented as threshold, in decibels; ratio, where the antecedent number gives the number of decibels a sound may exceed the threshhold in order to be compressed to the consequent number; and attack and release time, in milliseconds.
A compressor with a threshold of -25 decibels, a ratio of 4:1, an attack time of 10 milliseconds, and a release time of 100 milliseconds, would mean that any sound hitting the compressor above -25 decibels will be compressed, every 4 decibels above the threshold will be compressed to 1 decibel over the threshold, that the compressor will allow a ramp-up of 10 milliseconds after a sound has passed over the -25db threshold to reach full compression, and it will allow 100 milliseconds after the sound has passed under the -25db threshold to fully stop applying compression.1 In general, if you wanted to even out the dynamics of a recording that had a very wide dynamic range, you would want a high ratio and a low threshold (but the result would almost certainly sound heavily compressed.) There are other common features of compressors like knee or make-up gain, which I’ll skip today.
IV. Quick reflections on EQ and Compression
In the context of this talk, my goals in explaining the mechanics of EQ and compression are, first, to demonstrate that a variety of critical timbral choices are made by mixing engineers from the very first steps of the recording process; it is not uncommon for an audio engineer to exert more control over the tone of an instrument than the performer themselves, and we of course would hope such decisions were made collaboratively. In interviews, engineers and artists routinely describe thinking about the narrative of the song they’re recording in making these creative choices: in terms of creating a sound stage, emphasizing particular instruments or qualities of sound to expressive effect, and to creating a “vibe.” (Though there is also a lot of use of words like “character” and “tone” which I find frustratingly vague.)
The second point is to underscore a major challenge for music analysts, which is that these engineering choices are fundamentally unknowable from the resultant audio alone. One solution is to encourage ethnographic work in the recording studio, which does produce very interesting and important work but limits the analyst to writing about sessions they can discover in advance and attend in person. To a certain extent I’m about to model that kind of analysis. But I wonder what exactly the explanatory value of knowing every facet of the recording process is for music analysis, given that a very broad range of techniques could yield very similar sounds. If an analyst can nearly always find a way to link a sounding result to a particular engineering technique, I do not see how a consistent and analytically meaningful causal link between technical practice and sounding result could be established, beyond creating broad groupings of techniques.
Those of us who are wary of music analysis that is unduly preoccupied with the supremacy of authorial intent might even greet this as liberating, even if it cuts against music theory’s disciplinary predilection toward prescription.
V. Let’s mix some drums!
First, caveats: These speakers are so, so far from an optimal listening situation. The mixing I am doing is simplistic, so as to be easier to follow, and over-dramatic, so as to get my points across in this suboptimal situation. I’ll only be using stock plug-ins found in Apple’s Logic Pro.
So: Let’s say a client has sent the following drum performance and asked me, the mixing engineer, to make the drums sound huge, punchy, lots of attack, a big rock sound.
Let’s listen to the recording on its own. All I’ve done in advance is level out the gain of each track a bit.
The first thing I notice is that these recordings have a decently wide dynamic range and do not sound tremendously bright; they’re a little flat, a little lifeless, definitely not very punchy.
Here’s what they sound like after mixing (and in my demo I tried to focus on the idea that drum body, drum resonance, and stick attack are associated with different parts of the frequency spectrum; about the use of slow attack times and fast release times for making drums sound bigger and more forceful; about stereo spread; bus compression.)
This is me playing, and I deliberately played relatively quietly to try and emphasize the disconnect between exertion-in-performance and exertion-in-recording. Here’s the video:
VI. Embodiment
So far I’ve argued that audio equalization and compression are creative and expressive techniques that alter listener perceptions of three intertwined attributes: material, space, and effort or exertion. One way of explaining how they do that is to focus on the tools and techniques themselves, the aesthetic questions those tools might elicit, and the decisions those tools afford, and that’s what my mixing example was meant to show. I now want to look at some recent research on embodied perception/cognition to venture a corollary explanation as to how this works from a listener-oriented standpoint.
For a listener to hear the timbre of a bright and loud snare drum as an index for gestural exertion and material, I think they need to ask the question “what would it feel like were I to do this action to this thing in this space?” They can attend to this mode of relational engagement consciously, or not; and this mode of ecological listening does not foreclose on other (perhaps ineffable) features of listening in excess of attention to physicality, material, and so on. Rather, we are entering the realm of imagination, in which listeners have creative agency over the formation of meaning with these sounds. What I find most significant about this is that it opens up paths of engagement with sound that not only draws attention to embodied + ecological components of meaning-making but considers whether a listener might transcend them, and whether facilitating that transcendence might be a poetic through-line in the work of many artists in the recording studio.
This formulation is directly indebted to the work of Arnie Cox on mimesis and embodied music cognition. What I am describing is an example of what Cox calls overt or covert mimetic motor imagery (MMI). He posits that MMI can be:
Intramodal — accurately matching a heard and imagined action like piano playing with the motor activity that would produce it
Cross-modal — imagining a piano melody by analogy to the voice, through subvocalization
Amodal — modeling the tension and tightness (or looseness and relaxation) in the abdomen or shoulders that would accompany a particular series of gestures.
Cox’s account places special focus on vocality and subvocalization: the voice is considered the metaphoric source domain for the vast majority of instrumental sounds.
Zachary Wallmark has likewise written in his excellent new book on timbre that “we understand many dimensions of timbre via mimetic similarities to vocal expression.” (2022, 32). and that “Physical exertion leads to acoustical artifacts that are often heard as ‘noisy’…Noisy timbre is typically perceived as an acoustic index for heightened bodily arousal and exertion.”
In the drum mixing example, compression actually added to the signal some distortion, the paragon of noisy timbre, and this was part of how I made the drums sound more effortful.
But we also made changes to the sound that I am asserting change perceptions of the material manifest in traits like brightness or attack or stick sound. This is where I think there is room for further growth in vocal-oriented theories of embodied perception. I want to gently question the ontological priority of the voice: its priority over amodal forms of exertion, over materials that might be co-constitutive of sound and its timbral meanings, and as a fixed perceptual constant. The voice may not be the immutable yard stick that music theorists sometimes imply it to be.
For example: A cello heard cross-modally through subvocalization carries with it the residue of wood, string, and hair, and this materiality penetrates our vocality, merges with it, augments it. It does this in a way that is meaningfully different from an intra-modal expression of similar material-affective mappings. Observing this interpenetration leads me to question the fixity of the voice, and to imagine the radical contingency and manifold potentialities of the voice itself. Nina Sun Eidsheim’s work has drawn attention to this in her scholarship on timbre as a vector for social perceptions of difference. “While the voice is materially specific, a specific voice’s sonic potentiality…and indeed its execution, can exceed imagination.” (7). Later Sun Eidsheim writes: “Voice is not singular; it is collective. Voice is not innate; it is cultural. Voice’s source is not the singer; it is the listener.”
Cox’s mimetic hypothesis gestures tantalizingly toward similarly expansive potentialities. He describes hearing pitches higher than he can sing as “thrilling” and writes “I believe that this feeling comes in part from feeling something of what it would be like to transcend my usual limitations.” (55) and that our corporeal faculties for empathy and mimesis point to “the capacity to extrapolate from direct experience and to transcend, in imagination, one’s physical limitations via MMI” (56).
As technologies of augmentation, EQ and compression (alongside the other tools of the modern recording studio) may enable wholly novel affective states or feelings inspired by contradictory, chimerical, or fantastical aural representations of exertion, material, or space. Indeed I think that this transcendental potential has been known, at least avant la lettre, to artists and musicians working with studio tools for some time and is a central aesthetic current in a lot of recorded music.
In the case of the drums, that transcendental disposition could mean the feeling of playing faster and louder than my muscles are capable of playing. It could mean imagining playing drums that are of a particular size or shape or material. It could mean having a feeling of amodal tightening or tension that upon release yielded something massive, virtuosic, triumphant, powerful.
However conceived, it’s an example of an experience that feels in excess of my bodily capabilities and yet rooted in them; it is an experience that leads me to ask, consciously or unconsciously, about my corporeal self, its contingencies and potentialities, its relation to other selves and to its ecology; and it is an experience that is mediated by technologies of the studio and thus enabled by them.
Selected Bibliography
Cox, Arnie. 2016. Music and Embodied Cognition: Listening, Moving, Feeling, and Thinking. Bloomington, IN: Indiana University Press.
De Souza, Jonathan. “Timbral Thievery: Synthesizers and Sonic Materiality.” in The Oxford Handbook of Timbre, ed. Emily Dolan and Alexander Rehding. Oxford University Press
McAdams, Stephen. 2013. “Musical timbre perception.” in The Psychology of Music, ed Diana Deutsch. London: Elsevier Press.
Snoman, Rick. 2012. Dance Music Manual. Routledge.
Sterne, Jonathan. 2003. The Audible Past: Cultural Origins of Sound Reproduction. Duke University press.
Sterne, Jonathan and Tara Rodgers. 2011. “The Poetics of Signal Processing.” differences 22.2-3: 31-53.
Sun Eidsheim, Nina. 2019. The Race of Sound: Listening, Timbre, and Vocality in African American Music. Duke University Press
Välimäki and Reiss. 2016. “All About Audio Equalization: Solutions and Frontiers.” Applied Sciences 6:129.
Wallach, Jeremy. “The poetics of electrosonic presence: recorded music and the materiality of sound.” Journal of Popular Music Studies 15.1: 34-64
Wallmark, Zachary. 2022. Nothing But Noise: Timbre and Musical Meaning at the Edge. New York NY: Oxford University Press
Zagorski-Thomas, Simon. “Spectromorphology of Recorded Popular Music.” in The Relentless Pursuit of Tone, ed. Robert Fink, Melinda Latour, Zachary Wallmark. New York NY: Oxford Unviersity Press
Sincere thanks to Matt Sargent for suggesting a clearer way to phrase this; edited accordingly.
That Arnie Cox book looks really interesting, will check that out!
Small philosophical nitpick: I think you meant to say "transcendent" instead of "transcendental" (pure conditioning structure).
just in case Twitter goes down 4evah: billsallak@gmail.com for all your bill sallak needs